RAG (검색 증강 생성) 사용법 - LangChain으로 RAG기반 지능형 Q&A 웹서비스 개발하기
AI 챗봇이 오래된 정보로 답변하거나, 전문 지식이 필요한 질문에 피상적인 대답만 하는 경험이 있으신가요? 이는 현재 AI 기술의 한계를 보여주는 전형적인 사례입니다. RAG(Retrieval-Augmented Generation)는 이러한 문제를 해결하는 혁신적인 기술입니다. 실시간으로 최신 정보를 검색하고 AI의 추론 능력과 결합하여, 항상 정확하고 맥락에 맞는 답변을 제공합니다.
이 가이드에서는 LangChain과 Streamlit을 활용해 실제 작동하는 RAG 기반 Q&A 웹서비스를 개발하는 방법을 배웁니다. 위키피디아의 방대한 지식을 실시간으로 활용하는 지능형 시스템을 직접 구축해보세요. 그럼 AI 개발의 새로운 지평을 여는 여정을 시작 해보겠습니다.
1. RAG (검색 증강 생성) 이란?
RAG는 'Retrieval-Augmented Generation'의 약자로, 한글로는 '검색 증강 생성'이라고 번역할 수 있습니다. 이 기술은 기존의 생성형 AI 모델에 실시간 정보 검색 능력을 결합한 혁신적인 접근 방식입니다.
RAG에 대해 궁금하다면 RAG란 무엇인가? 챗GPT의 한계를 극복하는 혁신적인 AI 기술의 내용을 참고하세요.
이 글에서는 LangChain을 사용하여 실제로 RAG 시스템을 구현하고, 이를 웹서비스로 배포하는 방법을 단계별로 알아보겠습니다.
2. 준비 사항
시작하기 전에 다음 항목들이 필요합니다:
- Python 3.7 이상
- pip (Python 패키지 관리자)
- OpenAI API 키 (또는 다른 LLM API 키)
3. 환경 설정
먼저 필요한 라이브러리들을 설치합니다:
pip install langchain langchain_openai chromadb streamlit wikipedia
4. RAG 시스템 개발
이제 RAG 시스템의 핵심 구성 요소들을 구현해 보겠습니다.
4.1 필요한 모듈 임포트
먼저, 필요한 모든 모듈을 임포트합니다. 각 모듈은 RAG 시스템의 특정 부분을 담당합니다.
import os
from langchain_community.document_loaders import WikipediaLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
WikipediaLoader: Wikipedia에서 문서를 로드합니다.RecursiveCharacterTextSplitter: 긴 문서를 작은 청크로 분할합니다.OpenAIEmbeddings: 텍스트를 벡터로 변환합니다.Chroma: 벡터 데이터베이스로 사용됩니다.ChatOpenAI: OpenAI의 GPT 모델을 사용합니다.RetrievalQA: 검색-질문 응답 체인을 생성합니다.PromptTemplate: 사용자 정의 프롬프트를 생성합니다.
4.2 OpenAI API 키 설정
OpenAI API를 사용하기 위해 API 키를 환경 변수로 설정합니다.
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
실제 사용 시에는 "your-api-key-here" 부분을 여러분의 실제 OpenAI API 키로 교체해야 합니다.
4.3 문서 로드 및 분할
이 함수는 Wikipedia에서 문서를 ��로드하고, 이를 작은 청크로 분할합니다.
def load_docs(query):
loader = WikipediaLoader(query=query, load_max_docs=1)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(documents)
return splits
WikipediaLoader를 사용하여 주어진 쿼리에 대한 Wikipedia 문서를 로드합니다.RecursiveCharacterTextSplitter를 사용하여 문서를 1000자 크기의 청크로 분할합니다. 200자의 오버랩을 두어 문맥의 연속성을 유지합니다.
4.4 벡터 저장소 생성
이 함수는 분할된 문서를 벡터로 변환하고 Chroma 벡터 저장소에 저장합니다.
def create_vectorstore(splits):
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
return vectorstore
OpenAIEmbeddings를 사용하여 텍스트를 벡터로 변환합니다.Chroma를 사용하여 이 벡터들을 저장하고 검색할 수 있는 데이터베이스를 생성합니다.
4.5 RAG 체인 생성
마지막으로, 이 함수는 실제 RAG 체인을 생성합니다.
def create_rag_chain(vectorstore):
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
prompt_template = """아래의 문맥을 사용하여 질문에 답하십시오.
만약 답을 모른다면, 모른다고 말하고 답을 지어내지 마십시오.
최대한 세 문장으로 답하고 가능한 한 간결하게 유지하십시오.
{context}
질문: {question}
유용한 답변:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(),
chain_type_kwargs=chain_type_kwargs,
return_source_documents=True
)
return qa_chain
ChatOpenAI를 사용하여 GPT-4 모델을 초기화합니다.temperature=0은 모델의 출력을 가능한 한 결정적으로 만듭니다.- 사용자 정의 프롬프트 템플릿을 생성합니다. 이 템플릿은 모델에게 어떻게 답변해야 하는지 지시합니다.
RetrievalQA를 사용하여 검색-질문 응답 체인을 생성합니다. 이 체인은 주어진 질문에 대해 관련 문서를 검색하고, 이를 바탕으로 답변을 생성합니다.
4.6 전체 코드
위의 함수들을 하나의 파일에 모두 저장합니다. 이 파일을 rag_functions.py로 저장합니다.
import os
from langchain_community.document_loaders import WikipediaLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from dotenv import load_dotenv
load_dotenv()
# OpenAI API 키 설정
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
def load_docs(query):
loader = WikipediaLoader(query=query, load_max_docs=1)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(documents)
return splits
def create_vectorstore(splits):
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
return vectorstore
def create_rag_chain(vectorstore):
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
prompt_template = """아래의 문맥을 사용하여 질문에 답하십시오.
만약 답을 모른다면, 모른다고 말하고 답을 지어내지 마십시오.
최대한 세 문장으로 답하고 가능한 한 간결하게 유지하십시오.
{context}
질문: {question}
유용한 답변:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(),
chain_type_kwargs=chain_type_kwargs,
return_source_documents=True
)
return qa_chain
이렇게 구현된 함수들은 RAG 시스템의 핵심 구성 요소를 형성합니다. 이들은 함께 작동하여 사용자의 질문에 대해 관련 정보를 검색하고, 이를 바탕으로 정확하고 관련성 높은 답변을 생성합니다.
5. Streamlit을 사용한 웹 인터페이스 구현
이제 Streamlit을 사용하여 간단한 웹 인터페이스를 만들어 봅시다. 다음 코드를 app.py 파일에 저장합니다:
import streamlit as st
from rag_functions import load_docs, create_vectorstore, create_rag_chain
st.title("RAG Q&A 시스템")
# 사용자 입력
topic = st.text_input("위키피디아 주제를 입력하세요:")
question = st.text_input("해당 주제에 대해 질문하세요:")
if topic and question:
if st.button("답변 받기"):
with st.spinner("처리 중..."):
# 문서 로드 및 분할
splits = load_docs(topic)
# 벡터 저장소 생성
vectorstore = create_vectorstore(splits)
# RAG 체인 생성
qa_chain = create_rag_chain(vectorstore)
# 질문에 대한 답변 생성
result = qa_chain({"query": question})
st.subheader("답변:")
st.write(result["result"])
st.subheader("출처:")
for doc in result["source_documents"]:
st.write(doc.page_content)
st.write("---")
st.sidebar.title("소개")
st.sidebar.info(
"이 앱은 RAG(검색 증강 생성) 시스템을 시연합니다. "
"위키피디아를 지식 소스로 사용하고 OpenAI의 GPT 모델을 통해 답변을 생성합니다."
)
6. 애플리케이션 실행 및 사용 방법
6.1. 애플리케이션 실행
터미널에서 다음 명령을 실행하여 Streamlit 앱을 시작합니다:
streamlit run app.py
브라우저가 자동으로 열리고 아래와 같은 화면이 표시됩니다.
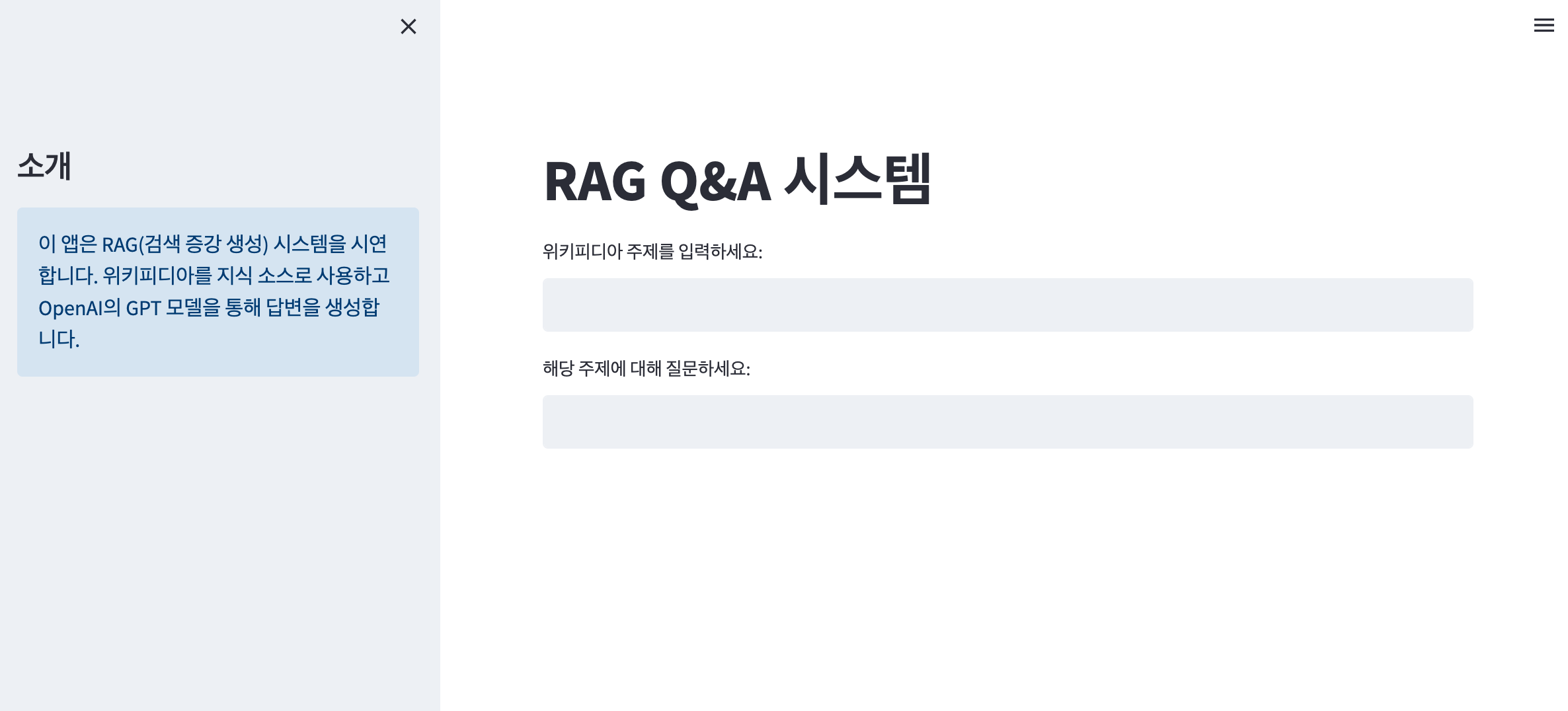
6.2. 사용 방법
- "위키피디아 주제를 입력하세요" 필드에 관심 있는 주제를 입력합니다 (예: "Artificial Intelligence").
- (주제의 경우 현재 영어만 지원합니다.)
- "해당 주제에 대해 질문하세요" 필드에 해당 주제에 대한 질문을 입력합니다.
- "답변 받기" 버튼을 클릭하여 답변을 생성합니다.
- 시스템은 Wikipedia에서 관련 정보를 검색하고, RAG를 사용하여 질문에 답변합니다.
- 답변과 함께 사용된 소스 정보가 표시됩니다.
아래 화면은 RAG 기반 지능형 Q&A 웹서비스의 결과 화면입니다. 블루베리(blueberry)에 대한 주제를 가지고 블루베리의 효능이 무엇인지에 대한 질문의 답변을 생성한 결과입니다.
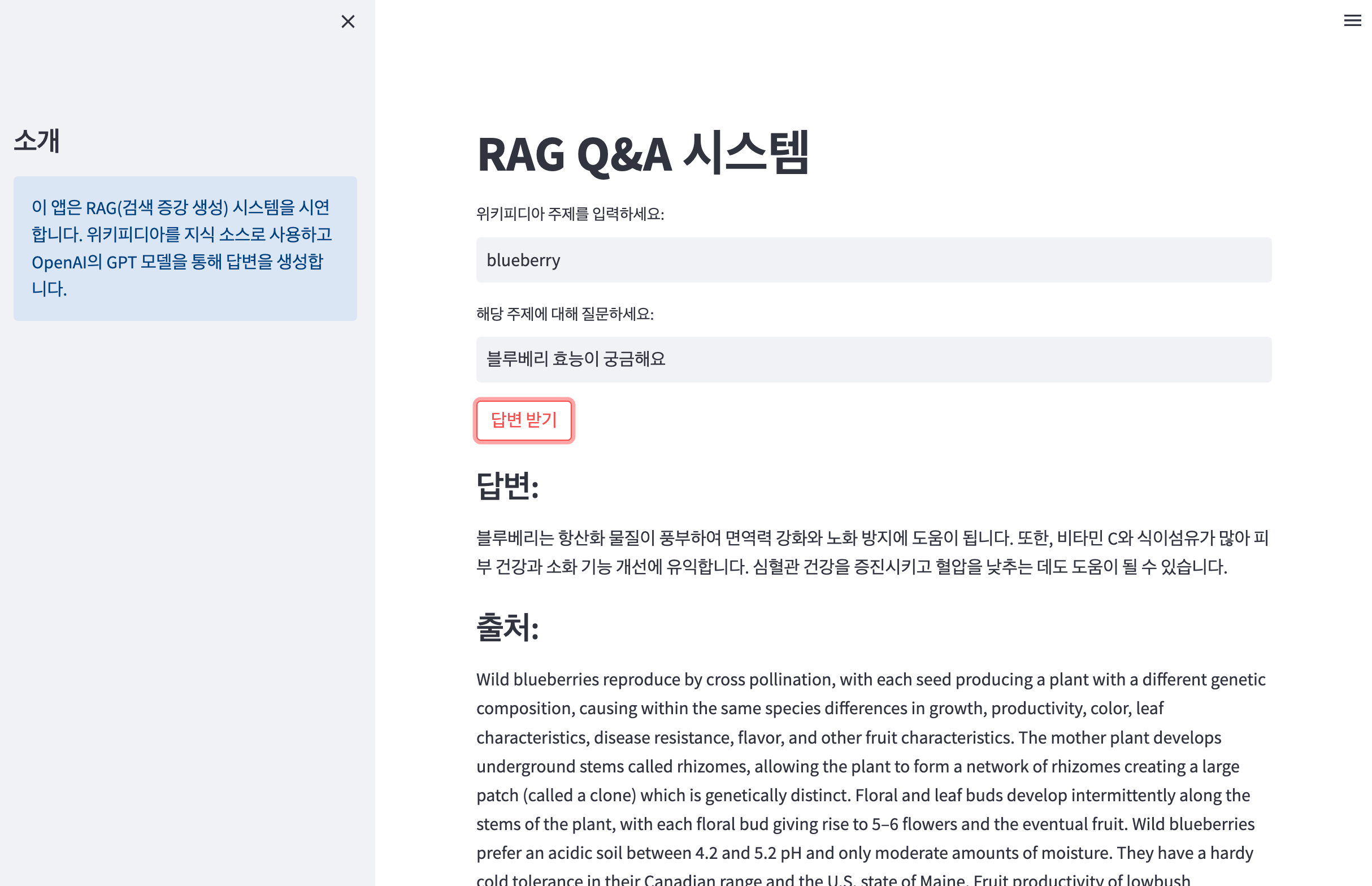
보시는 것 처럼 출처인 위키피디아에서 블루베리에 대한 정보를 검색하고, RAG를 사용하여 출처를 포함하여 객관적인 질문에 대한 답변을 생성합니다.
위와 같은 방법으로 사용자는 RAG 기반 지능형 Q&A 웹서비스를 사용할 수 있습니다. 이를 통해 사용자는 실시간으로 최신 정보를 검색하고, AI 모델의 추론 능력을 활용하여 정확하고 맥락에 맞는 답변을 얻을 수 있습니다.
7. 전체 적인 코드 설명
load_docs함수는 Wikipedia에서 문서를 로드하고 이를 작은 청크로 분할합니다.create_vectorstore함수는 문서 청크를 임베딩하고 Chroma 벡터 저장소에 저장합니다.create_rag_chain함수는 LLM, 검색기, 프롬프트 템플릿을 결합하여 RAG 체인을 생성합니다.- Streamlit 앱은 사용자 입력을 받고, RAG 체인을 사용하여 질문에 답변한 후 결과를 표시합니다.
8. 개선 및 확장 방안
- 다중 소스 통합: Wikipedia 외에 다른 데이터 소스를 추가하여 정보의 다양성을 높입니다.
- 캐싱 구현: 자주 요청되는 주제에 대한 벡터 저장소를 캐싱하여 성능을 개선합니다.
- 사용자 피드백 시스템: 답변의 품질에 대한 사용자 피드백을 수집하여 시스템을 지속적으로 개선합니다.
- 고급 검색 기능: 의미론적 검색, 다국어 지원 등 더 발전된 검색 기능을 구현합니다.
- 시각화 추가: 검색된 정보와 생성된 답변의 관계를 시각적으로 표현합니다.
9. 결론
이 튜토리얼에서는 LangChain과 Streamlit을 사용하여 기본적인 RAG 시스템을 구현하고 웹 애플리케이션으로 배포하는 방법을 살펴보았습니다. 이 예제를 기반으로 여러분만의 RAG 애플리케이션을 개발해 보세요. RAG 기술은 계속 발전하고 있으며, 이를 활용한 애플리케이션의 가능성은 무궁무진합니다.
RAG는 AI 시스템의 성능과 신뢰성을 크게 향상시키는 강력한 도구입니다. 여러분의 프로젝트에 RAG를 통합하여 더 스마트하고 정확한 AI 솔루션을 만들어보세요. 끊임없이 학습하고 실험하며, AI 기술의 새로운 지평을 열어가시기 바랍니다!